Risiken der Bilderkennung - Adversarial Attacks (DE)
In vielen alltäglichen Bereichen werden Machine Learning Algorithmen eingesetzt um dem Nutzer mehr Komfort zu bieten oder Arbeitsabläufe zu beschleunigen. Entscheidungen werden ihm abgenommen oder Inhalte so vorbereitet, dass diese nur noch bestätigt werden müssen. Beispiele mit Bezug zur Bilderkennung hierfür sind z.B. automatische Belegverwaltungen in Firmen oder die Kennzeichenerkennung unter öffentlicher Hand. Jede dieser Programme wird mit Input – dem Bild – gefüttert, woraus man ein entsprechendes Ergebnis basierend auf diesem erwartet. Bei der Belegverwaltung ist dieses beispielhaft der Betrag und Empfänger einer Rechnung, bei der Kennzeichenerfassung das extrahierte Kennzeichen und evtl. Randinformationen über das Fahrzeug.

Mit Adversarial Attacks wird versucht durch minimalste Modifikationen im Bildmaterial oder der Umwelt selber die Erkennungs-Algorithmen in die Irre zu führen. Diese optischen Fehler sind meist nicht einmal mit dem menschlichen Auge direkt erkennbar. Ziele dieser Attacken können es sein, den Algorithmus einfach auszuschalten und mit fehlerhaften Informationen zu täuschen, oder aber ihm ein plausibles – aber falsches – Ergebnis zu entlocken. Diese beiden Typen nennt man “non targeted” oder “targeted” Attacks.
Beispiele für “non targeted” Attacks:
- Freifahrtsschein auf allen Straßen: durch leichte optische Veränderungen an Kennzeichen und Karosserie könnten alle Kennzeichenerkennungssysteme und Geschwindigkeitsmessanlagen gezielt getäuscht werden. Ziel ist hier nicht das Annehmen einer anderen Identität, sondern lediglich die Erkennungswahrscheinlichkeit so stark zu reduzieren, dass das Daten als wertlos fallen gelassen werden.
Ziel der sog. “targeted” Attacks ist das Ändern von Output-Variablen des Bilderkennungs – Algorithmus. Dieses können z.B. sein.:
- Es wäre möglich Checks oder Banknoten herzustellen bzw. zu manipulieren, welche beim automatischen Einlesen in Bankautomaten (z.B. bei Bareinzahlung, Überweisung) die integrierte Bilderkennung täuschen und falsche Werte suggerieren.
- In naher Zukunft könnten Straßenschilder manipuliert werden um selbstfahrende Autos auszubremsen oder zu erhöhter Geschwindigkeit zu bewegen.
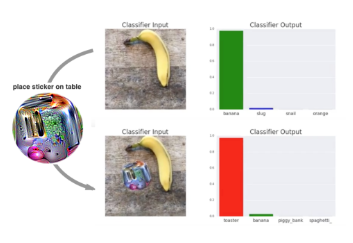
Mit diesem (siehe Abbildung oben) optisch sichtbaren – aber harmlos aussehenden – Patch lässt sich die Output-Klasse eines Erkennungs- Algorithmuses basierend auf dem vortrainierten Netzwerk- Models VGG16 effektiv beeinflussen. Dieses Model wird als Basis für viele Netzwerke in kommerzielle benutzten Softwares benutzt.
Bisher wurde die Anwendung von Adversarial Attacks nur theoretisch gezeigt, größere Attacken sind bisher nicht bekannt oder wurden geschickt geheim gehalten. Die gezeigten Beispiele sind allerdings nur ein kleiner Teil des technisch Möglichen.
Es gibt zwei Arten von Verteidigungsstrategien:
- Reaktive Strategie: Schulung eines anderen Klassifikators, um veränderten Input zu erkennen und abzulehnen. Dieses würde die Reaktionsgeschwindigkeit von Anwendungen negativ beeinflussen, da zwei Netzwerke durchlaufen werden müssten.
- Proaktive Strategie: Implementierung eines gegnerischen Trainingsprogramms.